Problem first: User Centricity at Steadybit

To build successful products, you can’t get past user-centricity. Especially true for a product-based startup like steadybit. This blog post covers how we work at steadybit and how we put our users first. It tells our story from the founding vision to an amazing product to be used and why you can expect to see a shift in the product coming in the following months.
The Journey Begins with a Vision
Let’s go back to the beginnings of Steadybit: As you may know, Steadybit was founded in 2019. Even if the name was different at the beginning* – the core of the founding vision still applies today:
Find weak spots in your system and fix them before they turn into problems.
The key to achieving this is democratizing Chaos Engineering and making it accessible to everyone in the tech industry.
The first steps for this vision were already pretty clear back then: The three founders (Benjamin, Dennis, and Johannes) realized that existing tools were quite hard to use and did not scale at an organizational level. From these insights, they developed Steadybit’s agent-based architecture, consisting of the agent that discovers the user’s system (so, yours!) and a central platform being the power of control. By discovering, for example, AWS, Kubernetes, or Docker context information of the targeted system, the user can very easily specify the exact target and put it into turbulent conditions. It also has features designed for organizational use, such as SaaS and on-prem support, as well as Role-Based Access Control (RBAC).
The Unconfirmed Vision
Nevertheless, the next steps, aligned with the vision, were far more unclear and uncertain. This is natural because Steadybit, as a newly founded startup, is subject to two primary principles of startups.
#1 Startups are Temporary Organizations
Startups are temporary organizations that exist to search for a repeatable and scalable business model (Steve Blank, “The Startup Owner’s Manual”). The challenge is to find that business model before running out of money. So, in simple terms, the key challenge is to solve a problem that creates value – so that someone is willing to pay for this solution (known as problem/solution fit). The challenge of scaling it into a product/market fit comes only afterward.
#2 No Direct Path to Problem/Solution Fit
To nail down the problem and then solve it, you need to take additional detours and loops. These help you to learn, pivot and discard solutions – which reduces uncertainties and risks on the way to scaling up later (Alexander Osterwalder & David J. Bland, “Testing Business Ideas”).
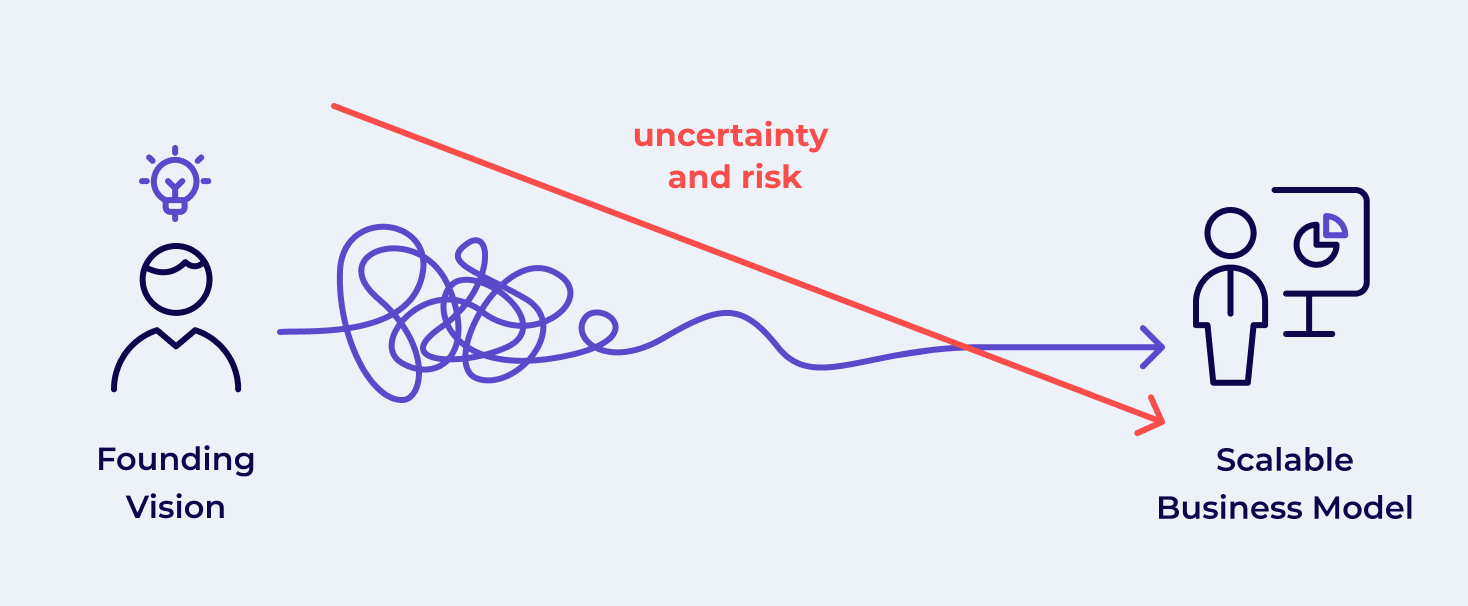
(based on Alexander Osterwalder & David J. Bland, “Testing Business Ideas”)
This inevitably means that even our initial founding vision is just a hypothesis that needs to be validated. Only when we have achieved enough understanding, certainty, and confidence in the problem, we can find a solution, build a loved product, and scale a business that offers it.
Our Approach: Product first
The matching approach we use to validate the founding vision and find a business model is “product first, sales later”. That is, trying to build a product that solves a problem, thus, creates value and is desirable to the market. The selling part is neglected first.
An alternative approach is to reduce the focus on the problem and increase the effort on saling the founding vision (“sales first, product later”). The idea is to make the market want what you have built, no matter how good your product really is. However, this approach is usually not sustainable as a competitor will always have a better product or puts more effort into moving the market in their direction.
Building a Product that is Loved
So how do you put the focus on the product? How do you build a product that customers love? According to Alexander Osterwalder and David J. Bland, we must hit the “sweet spot of innovation”. This is the spot where feasibility (“Can we build this?”), viability (“Can we make money with it?”) and desirability (“Does anyone even want us to build it?”, “Is it enjoyable to be used?”) meet.

(based on Alexander Osterwalder & David J. Bland, “Testing Business Ideas”)
Being a company deeply rooted in engineering, the feasibility issue is not a blocking element, and as sales/viability is not the focus at the moment, the missing part was desirability. That’s also why the three founders asked experts from UX&I for additional support. UX&I is a User Experience consulting company focusing on deep tech and enterprise software. Their goal is to empower people by putting complex technology into users’ service. So, exactly what we need to cover!
Approaching Desirability
Desirability goes hand in hand with user-centricity. That is why we strongly rely on user-centricity and user experience. Starting with the first and most important UX rule:
You are not the user.
Once we had internalized this, it was clear that we could only find answers to our questions through research and exchanges with potential users. We can only tackle the desirability challenge by understanding the users’ context and empathizing with their pains, needs, fears, and goals. A suitable method for that is semi-structured interviews.
Get Insights Using Interviews
When trying to gain relevant insights through interviews, it is important to focus on the problem space, meaning the user’s jobs, pains, and gains. So, instead of rushing into solutions too fast, it is important to listen carefully to what the interviewee is saying and drill down further by asking deeper questions (e.g., “How do you do it?”, “What tools do you use to do it?”, “Who does it?”, “How do you know it is done?”).
To be better prepared and not lose focus in the interviews, it also helps to think about what we actually want to learn and discover (so-called hypotheses). Here are two examples of our hypotheses:
Hypothesis 1: Customers want to reduce downtime because Less downtime inevitably means more satisfied (end) customers
Hypothesis 2: Users need a simple tool to perform Chaos Engineering
Oh, and very important to note: We always conduct the interviews with two people, one asking the questions and the other writing down everything that has been said. Being alone and taking care of both is very challenging. There is a high chance that you will miss something or only get keywords instead of a full interview transcript.
Organize Insights with Affinity Mapping
Pretty soon after we did the first interviews, we realized that only the transcripts were not helpful. About 3 to 5 pages per interview multiplied by dozens of interviews leads to an endless stack of pages nobody wants to read all the time. To solve this, there is a pretty cool method called Affinity Mapping that helps to structure and group the statements of the interviews and, in the end, conclude on our mentioned hypothesis. If you want to understand how the method works, UX&I published an Affinity Mapping cheat sheet on their blog. In addition, they also provide more background information about the underlying UX concepts, helping to come up with the hypotheses.
What we learned
So, enough explanation, what have we found out? Below is a summary of the exemplary hypotheses and a surprising discovery. Covering all findings would go beyond the scope of this blog post and is not practical, as we will build them into the Steadybit product anyway. If you want to learn more, don’t hesitate to ask for a quick product demo.
#1 Users are afraid to break something
This was one of the most important discoveries, which we had not considered before. Breaking something by doing Chaos Engineering that doesn’t recover afterward is critical. Even if you do it in a non-production environment, it can lead to blocking your teammates – and you don’t want to be responsible for that.
#2 Downtime can be OK
Based on hypothesis 1 (“Customers want to reduce downtime”), we discovered that not every customer needs zero downtime. Downtime is always a trade-off between effort and benefit. Being down can be totally acceptable if you handle it e.g. via additional discounts for your end customers. Even so, the awareness and transparency of preventive measures is low as no single person is responsible for reliability. In contrast, security, for example, has a lot of attention these days as no one can afford to have gaps in this area.
#3 Shortcut Needed to Improve Resilience
Hypothesis 2 (“Users need a simple tool to perform Chaos Engineering”) is true for Chaos Engineering Experts, who demand it. Most potential users (e.g., developers or operations) are only interested in the results and how to resolve the findings. This is natural as they get incentivized, e.g., for building applications, and are measured by engineering velocity, not by reliability or discovered dark debt.
Conclusion
Thanks to the user-centered approach, we were able to learn and understand the users’ needs, goals and problems, which helped us to validate and improve the Steadybit product. Based on these insights, we discovered how important it is for users to find an appropriate balance between engineering velocity and reliability. This is a growing need due to the movement towards cloud-based microservices, where you can no longer count on a controlled, stable environment. The key is to create more awareness by building a culture of resilience that provides transparency, teaches skills and facilitates communication and collaboration. Benjamin has published another blog post about the evolution of Chaos Engineering on this.
Looking at our working model in general, it was essential to know what teams are good at and accept blind spots. Filling these adequately through an interdisciplinary approach is an important step in product development. But it is even more important to get out of your comfort zone and accept that your ideas are just that – ideas. They need validation and proof – and you have to be willing to accept throwing them away if they don’t solve anyone’s problem.
*: Steadybit was originally called Chaosmesh, but due to the expansion of the focus on Resilience Engineering as part of the discovery, the company was renamed in 2020.

Get started today
Full access to the Steadybit Chaos Engineering platform.
Available as SaaS and On-Premises!
or sign up with

Book a Demo
Let us guide you through a personalized demo to kick-start your Chaos Engineering efforts and build more reliable systems for your business!