Have a question for us?
We’re here to answer any questions you have along the way. Just reach out!


TRUSTED BY COMPANIES WORLDWIDE





Identify, validate, and remove obstacles to your network and app reliability long before they affect your customers.
Take a proactive approach and mitigate the unexpected. Guide the product and engineering teams to fix instability at speed and at less cost.
Eliminate the financial and reputational costs of untested reliability. Get the assurance that when your customers want to buy, they can.
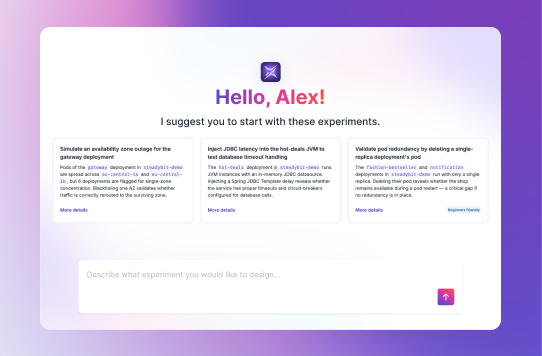
Say hello to SteadyBuddy, our Ai companion, and get in-context, fully integrated AI specialists throughout your reliability-testing setup, implementation, and maintenance.
In short, orchestrate Agentic-First Chaos Engineering to help you deliver reliability testing.
Check your alert coverage and accuracy under different conditions

Find and fix reliability issues before they introduce risks in production
Train with your systems to know what to expect and mitigate incidents quickly
Cloud Platform Engineer

Engineering Lead
Director of Software Engineering
Site Reliability Engineering Team Lead
@ Global Telecom Company

Site Reliability Engineer
Site Reliability Engineer
Director of Software Engineering
@ Global Ecommerce Company
SRE Team Lead
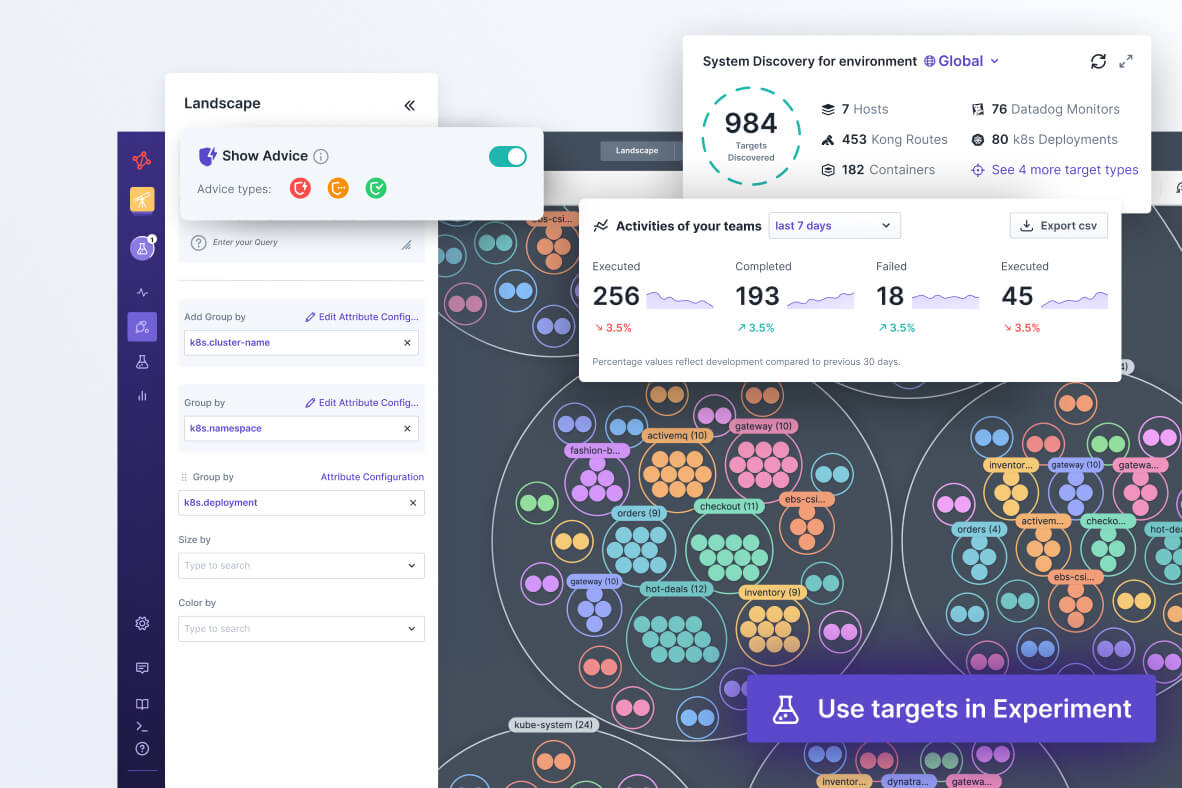
Let Steadybit’s automatic discovery feature build experiments/tests while simultaneously pulling the required metadata from your system. Or get advice on common issues and mitigations with our Reliability Advice feature. Use our intuitive query language to group and filter your targets. Get instant reliability advice on your application. Say goodbye to the blank page problem and have a Chaos Engineering program set up in a flash.
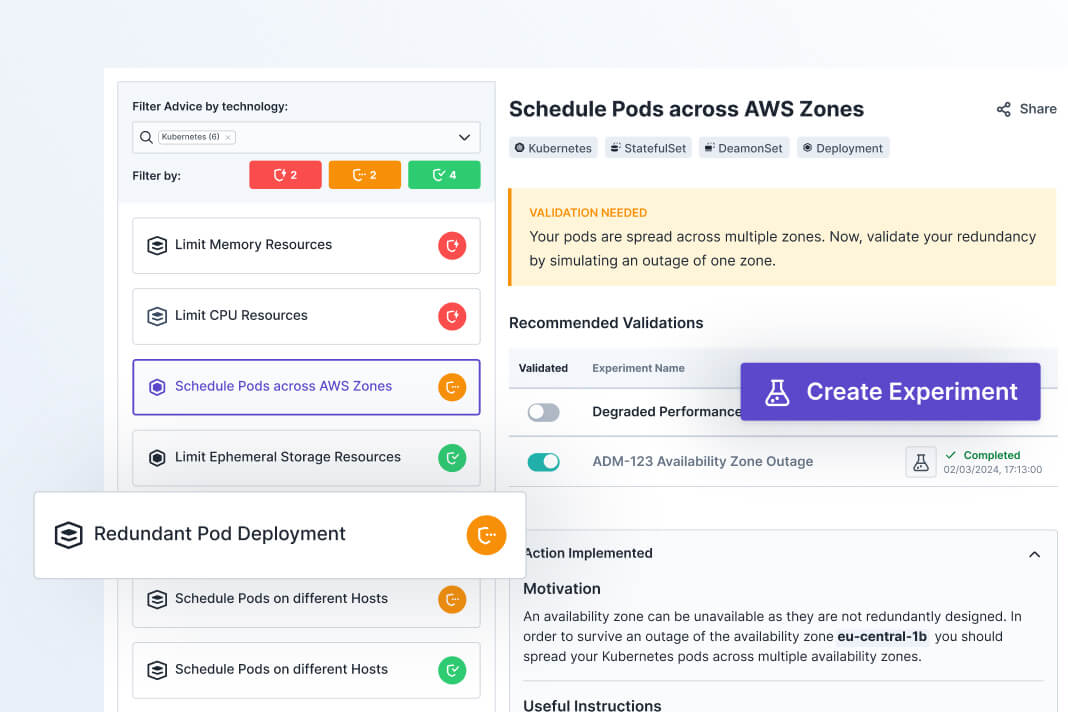
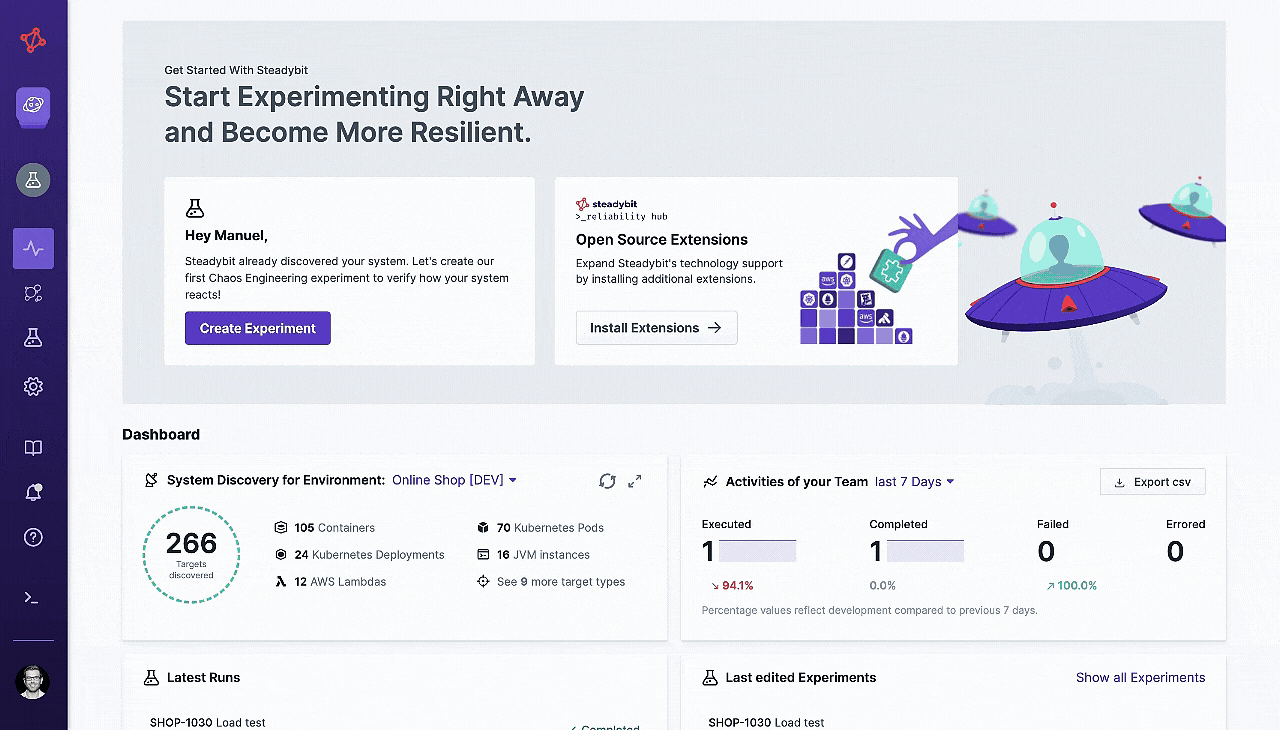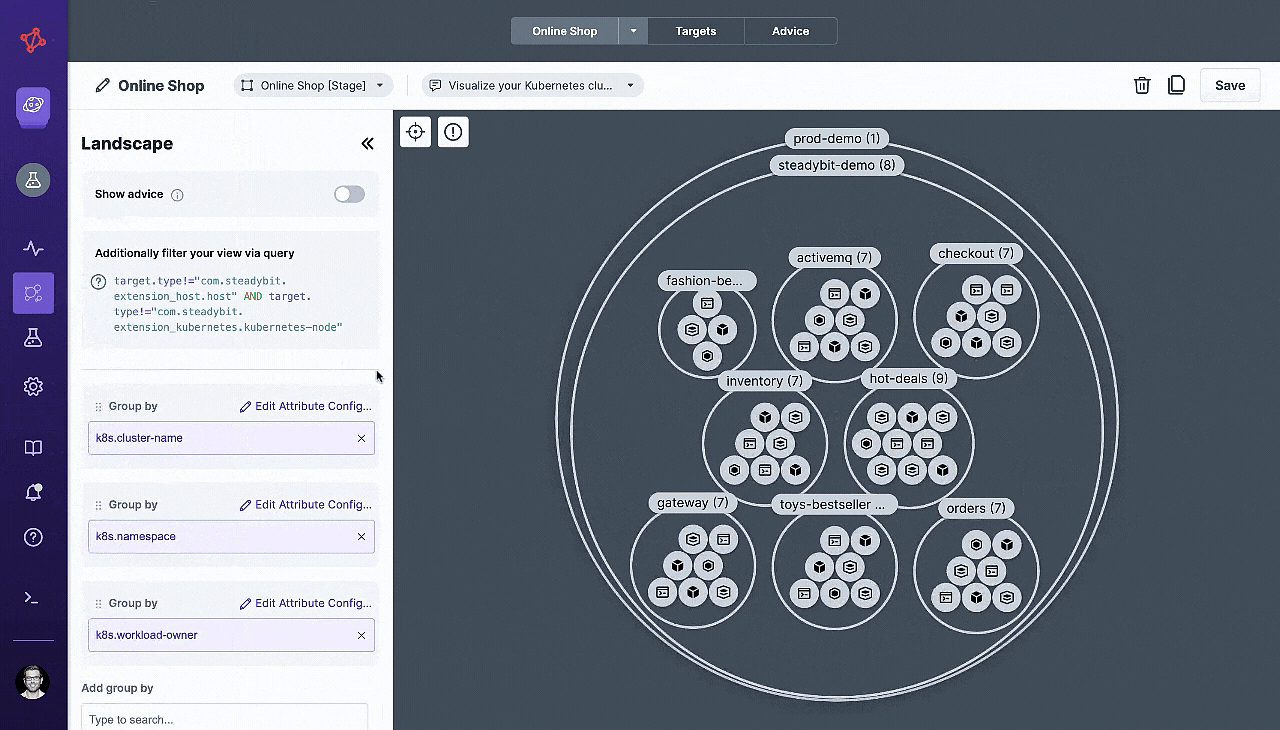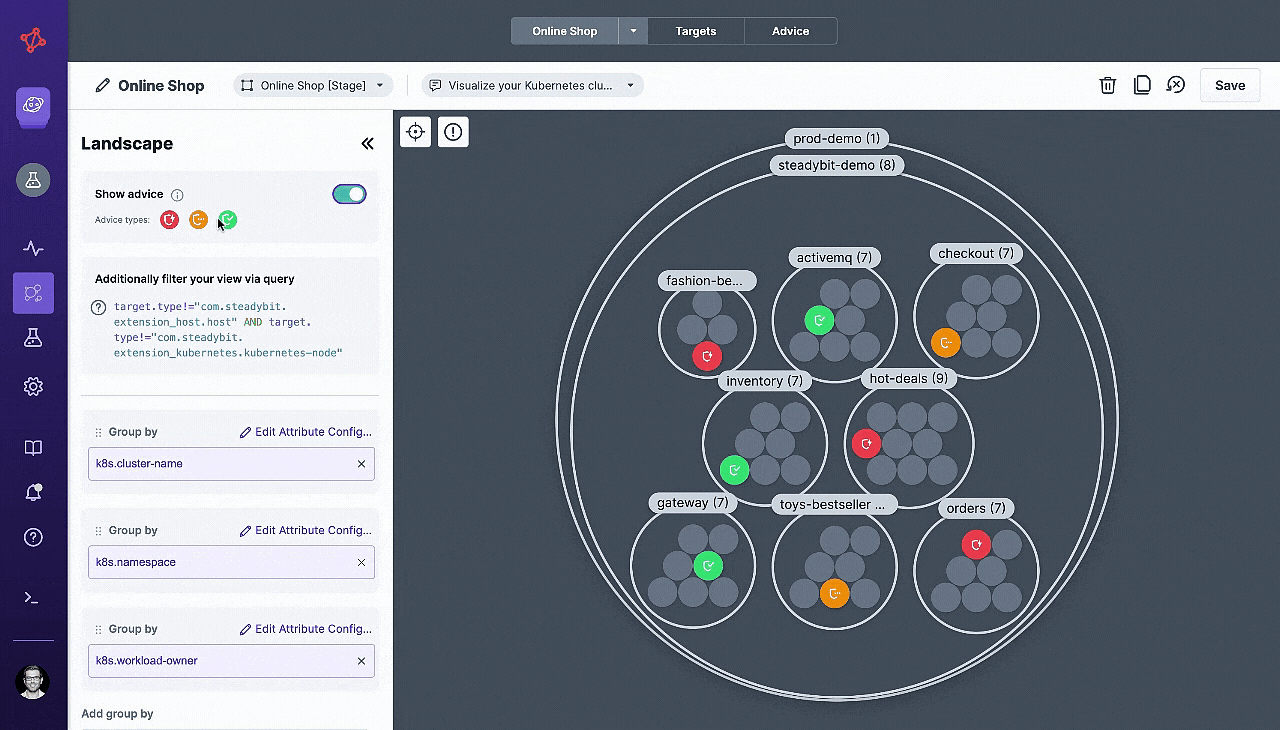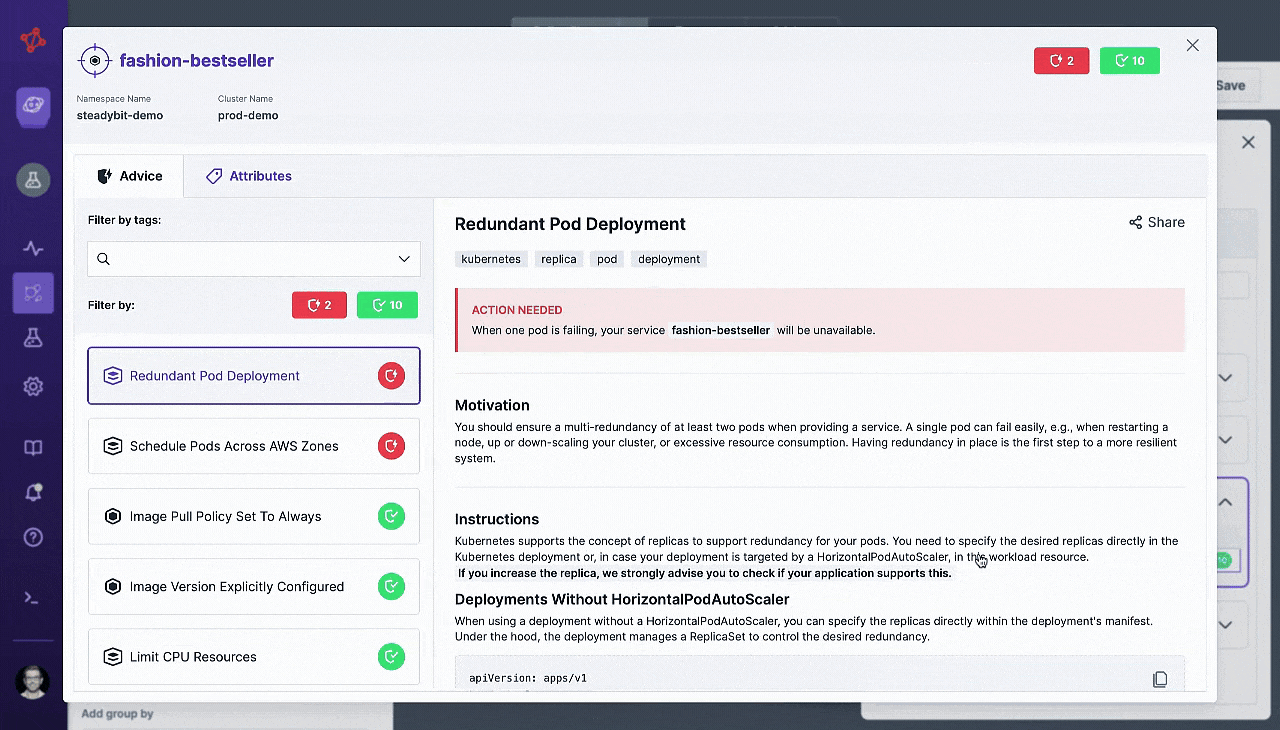
Once a weakness has been detected, get clear instructions on how to mitigate it right down to the code level. Deploy the fix and receive suggestions on what experiments/tests to perform next. Get guidance and start to find and fix vulnerabilities from the get-go.
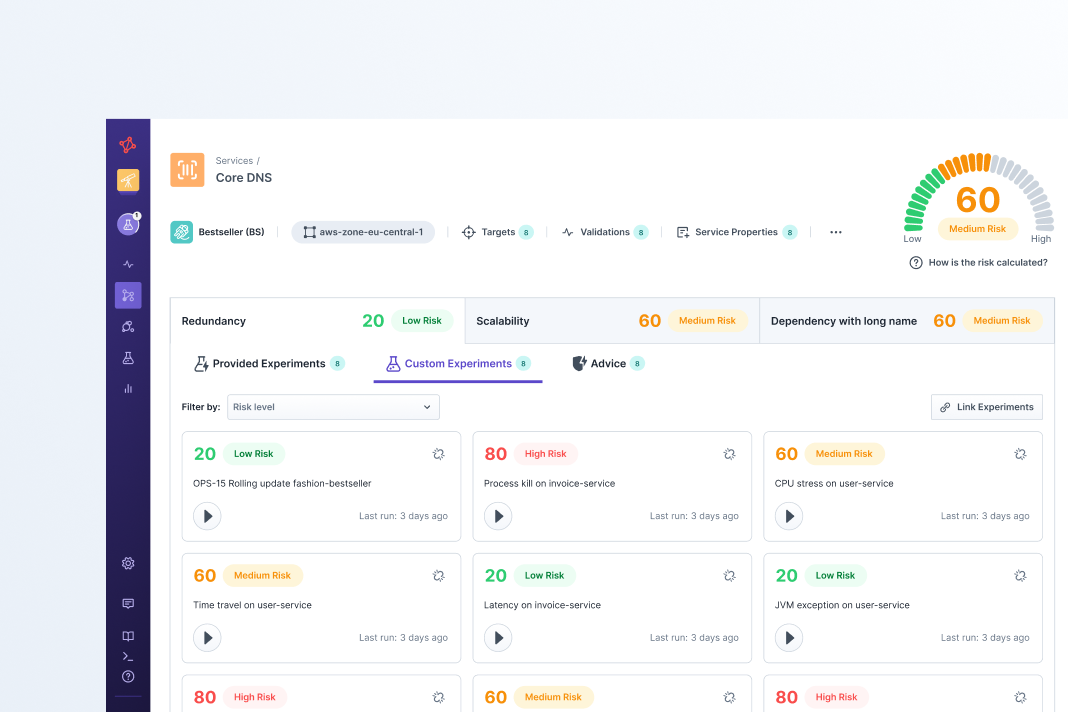
Instantly understand your reliability posture with reports. Prove you and your team’s worth with risk reduction metrics and reports while clearly articulating the return on investment you are providing.
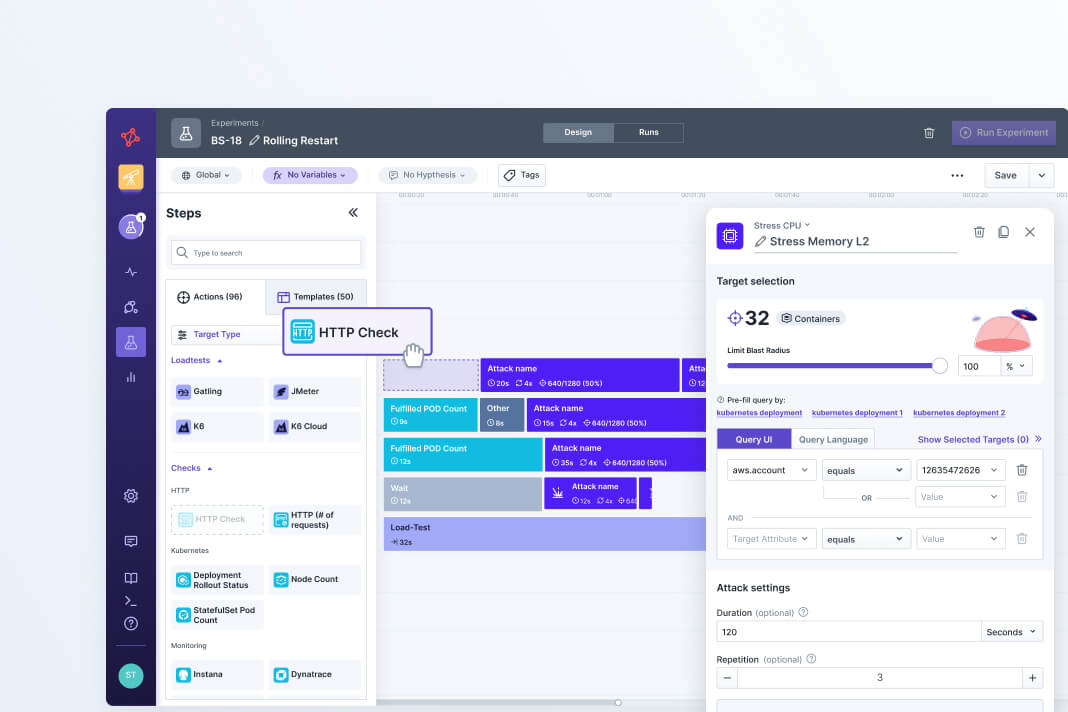
Take Steadybit’s out-of-the-box chaos engineering program and make it your own. Use our drag-and-drop designer, and add custom actions and extensions to run any type of experiment/test you want.
Drag-and-drop actions into the Steadybit experiment editor to create new reliability tests and iterate quickly.







Explore the Action Library
Browse open source actions that you can easily add to experiments.







Explore the Action Library
Browse open source actions that you can easily add to experiments.





Explore the Action Library
Browse open source actions that you can easily add to experiments.






Explore the Action Library
Browse open source actions that you can easily add to experiments.





Explore the Action Library
Browse open source actions that you can easily add to experiments.






Explore the Action Library
Browse open source actions that you can easily add to experiments.
Bring team members together to learn about their systems through controlled chaos engineering.
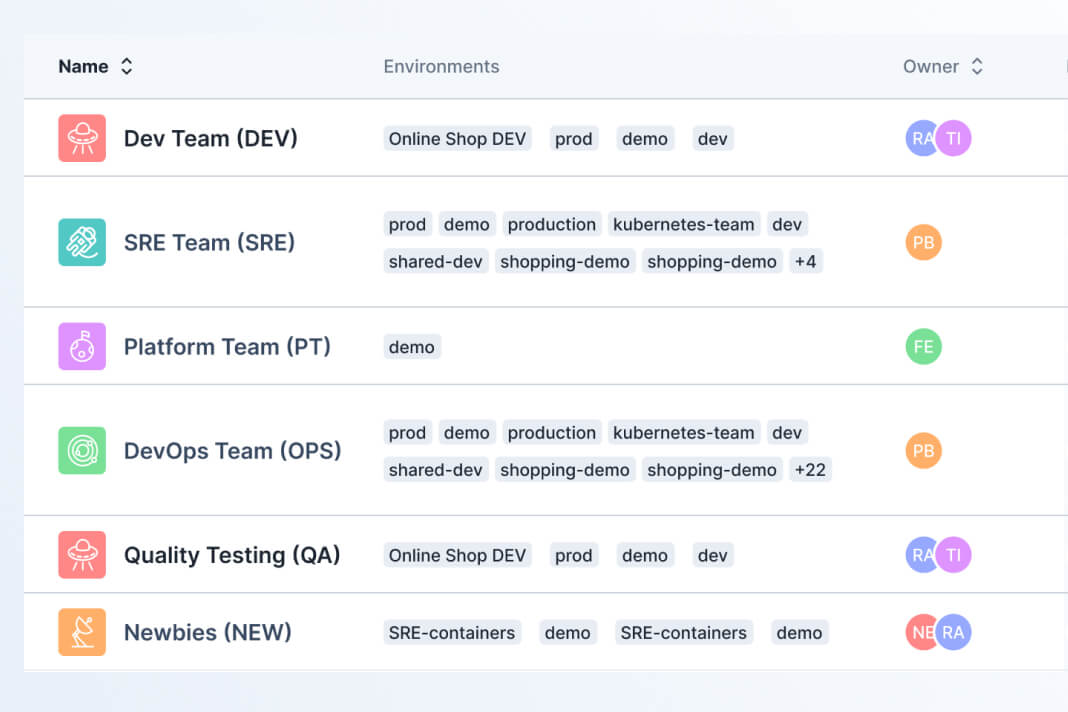
Set guardrails & fine-grained permissions
Define access and permissions for users to ensure safe testing.
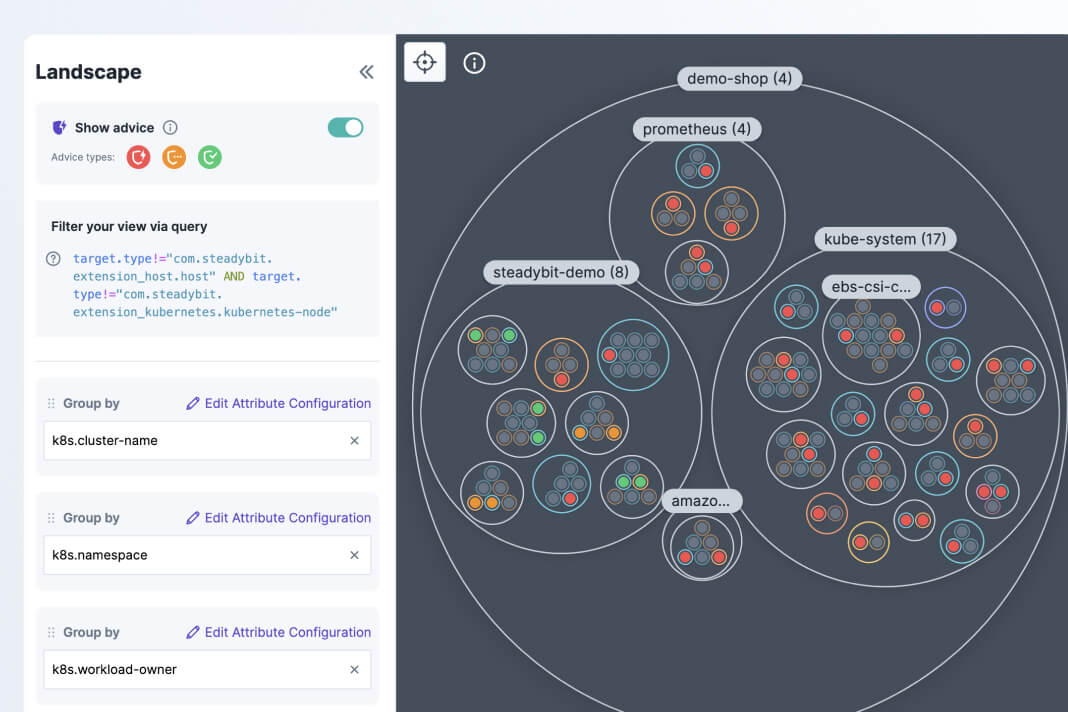
Automatically detect vulnerabilities
Assess whether your targets are compliant with reliability best practices.
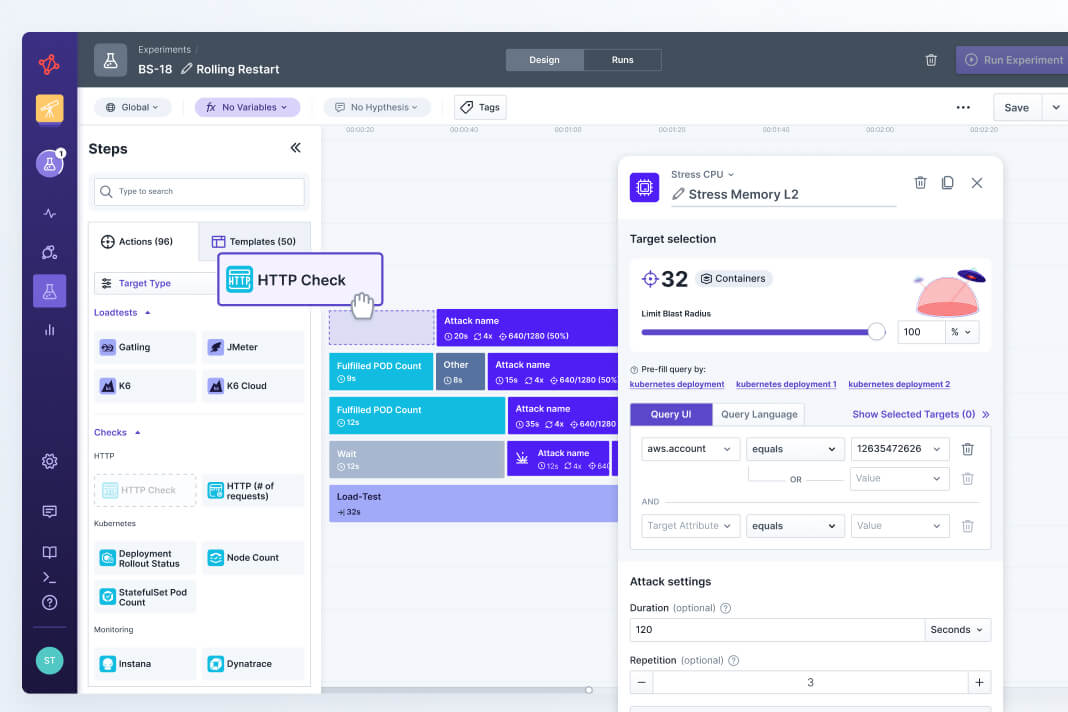
Run actions with a timeline-based editor
Start quick with templates for common use cases or build fully custom tests.
Just install the Steadybit agent on your network and add our open source extensions to match your tech stack.
We have supported SaaS and On-Prem deployments since Day 1.
Evaluating chaos engineering tools? Here are the most common questions we answer for teams.
Can we deploy Steadybit in On-Prem or air-gapped environments?
Yes, of course! From Day 1, Steadybit has offered SaaS and On-Prem deployment options with full feature parity. No other chaos engineering tool has more experience supporting On-Prem deployments.
Install the control plane and extensions in any environment seamlessly and start improving your reliability.
To learn more about our On-Prem support, you can read the installation details here.
How can we evaluate Steadybit to see if it's right for us?
If you’re not sure the best way to get started, a quick call with us can be helpful. We can answer technical questions you have and guide you on what we’ve seen work the best. You can schedule that here.
If you want to get into the platform and start playing around right away, we offer a free 30-day trial. You can either install agents and extensions directly on your systems or use our provided sample data to see how each of our features work. Sign up here.
If none of these sound right, just fill out our contact us form and provide us with more info. We’re here to help!
How do we add custom actions and extensions?
Steadybit is the most extensible reliability platform because it has a hybrid architecture that supports open source extensions.
Our ExtensionKits enable you to add custom actions, templates, targets, advice, and extensions. Write in your preferred coding language and start to customize Steadybit to fit your specific use cases and tech stack.
How does Steadybit automatically detect reliability vulnerabilities?
Our Reliability Advice feature continually analyzes all of your discovered targets and checks whether they are compliant with the best practices outlined in the “Advice” settings.
When you get started with Steadybit, there are 13 Advice checks out-of-the-box based on the best practices outlined by the open source tool, kube-score.
If you want to add checks based on internal standards or other best practices, our AdviceKit provides instructions on how to write your own custom Advice.
What prevents experiments from causing unintended damage?
To start, we have RBAC user permissions that let you limit the actions and targets that users can interact with. Group targets into defined testing environments and assign only the relevant teams to ensure least privilege access.
When designing experiments, you can select a blast radius for your targets. For example, you could specify that you only want to target 10% of the pods in a cluster. This is an easy way to ensure that your experiments start small with limited impact.
Before an experiment runs, you can configure pre-flight webhooks. These customizable checks allow you to ensure that all conditions are ready for your experiment to begin running.
When experiments are running, anyone in your organization is able to hit the “Emergency Stop” button. This will immediately rollback changes and ensure that you can respond fast.
With all of the features, you can set up controls and guardrails to enable experimenting with confidence.
We’re here to answer any questions you have along the way. Just reach out!
We’re bringing experts together to explore and define modern resilience engineering practices.
Benjamin Wilms sits down with Adrian Hornsby, a leading expert in chaos engineering, to discuss the challenge of the prevention paradox.
Read MoreBenjamin Wilms sits down with Russell Miles, a leading expert in the resilience engineering space, to discuss the definition of system reliability and the value of psychological safety.
Read MoreBenjamin Wilms chats with Casey Rosenthal, “The Chaos Engineering Guy”, about what it takes to develop a proactive approach to reliability.
Read MoreBenjamin chats with Carlos Rojas, author of “Resilience Engineering for the Cloud”, about how platform teams support proactive reliability efforts.
Read MoreSchedule a demo with our team to see a platform walk-through and get your questions answered.
